R语言处理表格数据(一)
目录
- 写在前面
- 1. Excel有上百列数据,把每列数据首尾相接合并成一个向量(一列)
- 2. 合并多个数据表(.csv)
- 3. 实现2个Excel表相同数据的关联,并提取相同数据到新表
- 4. 获取Excel表里面列名为TEM的所有数据并保存
- 5. 将文件夹中的.dbf文件转换为.xlsx文件
- 6. excel表格中生成重复数据
- 7. 表格数据按列合并!!!
写在前面
这是我新开的一个专题,专门用来记录我在处理数据的过程中遇到的一些问题,并且记录下我使用R语言处理表格数据(主要是.xlsx和.csv数据)的过程(包括一些“坑”),之后还会继续更新。如果能帮到你,顺便给博主点个赞吧!

1. Excel有上百列数据,把每列数据首尾相接合并成一个向量(一列)
需要处理的文件:
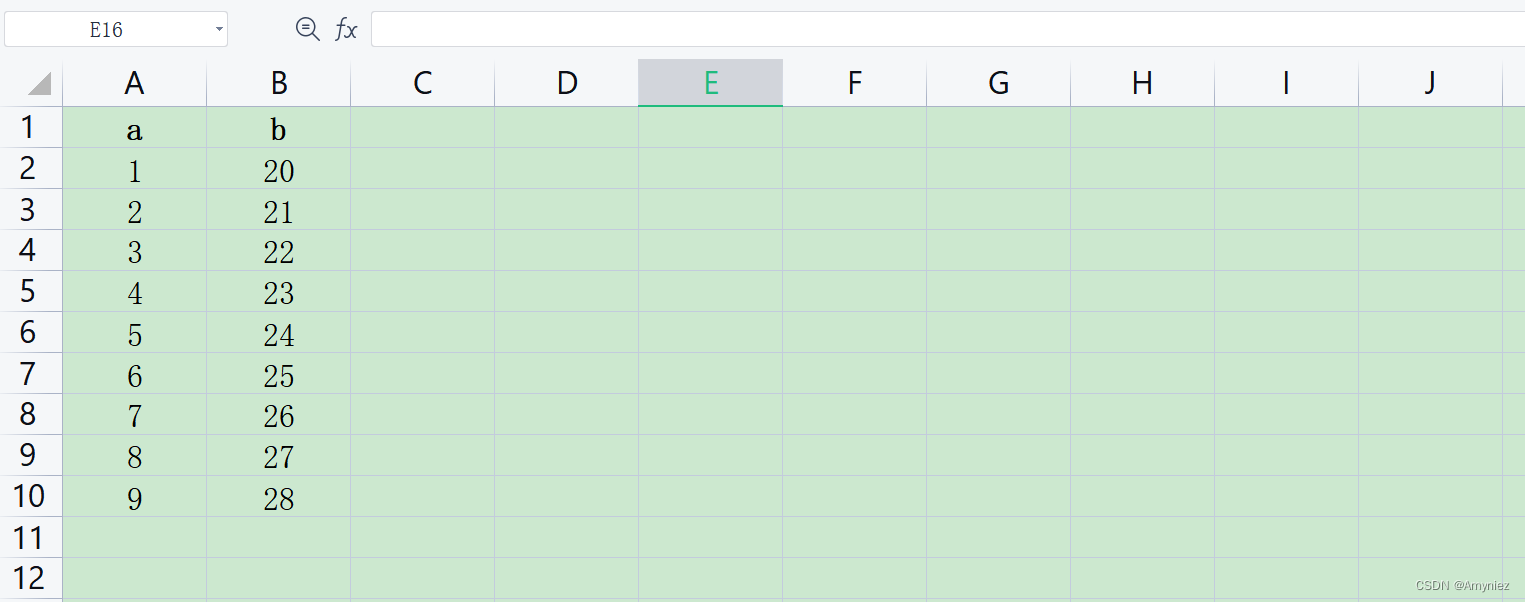
#---------------------------------------------------------------------
## @ author:JAckson Zhao
# @ time:2023/3/16 20:31:48
# @ description:Excel有上百列数据,把每列数据首尾相接合并成一个向量(一列)
setwd("D:/R语言")
library(readxl)
df <- read_excel("D:/R语言/1.xlsx")
df
# 将两列数据首尾相连合并为一列
merged_col <- paste(data$a, data$b, sep = "")
##法1:
# 将列a和列b首尾相接合并成一个向量
new_col <- c(df$a, df$b)
# 将新的向量转换为一个新的数据框
new_df <- data.frame(new_col)
new_df
##法2:
# 在 R 语言中,unlist() 函数用于将一个嵌套的列表或向量转换为一个单层的向量。
# 如果一个列表或向量是多层嵌套的,它的元素可以是列表或向量,则 unlist() 函数可以将所有元素拉平为一个单层的向量。
# 这个函数在处理数据集时非常有用,因为许多函数需要输入一个单层的向量,而不是嵌套的列表或向量
vector <- unlist(df)
new_df1 <- data.frame(vector)
new_df1
write.table(new_df,"dataframe.xlsx", sep = "\t", quote = FALSE, row.names = FALSE)
write.table(new_df,"vector.xlsx", sep = "\t", quote = FALSE, row.names = FALSE)
结果展示:
1、dataframe.xlsx:

2、vector.xlsx:

2. 合并多个数据表(.csv)
数据列表:
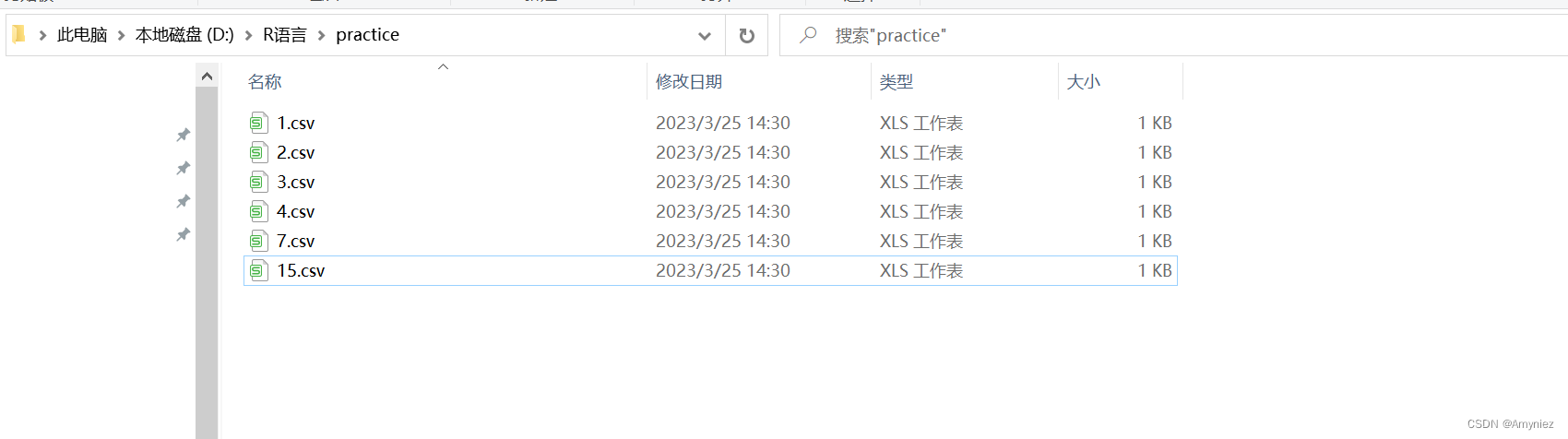

setwd("D:/R语言/practice")
# 设置文件夹路径
folder_path <- "D:/R语言/practice"
# 获取所有.csv文件的路径
file_paths <- list.files(folder_path, pattern = "\\.csv$", full.names = TRUE)
file_paths <- file_paths[order(as.numeric(gsub("\\D", "", file_paths)))]
file_paths
# 提取文件名中的数字,并用作列名
colnames <- gsub("\\D", "", basename(file_paths))
colnames <- paste("file", colnames, sep = "")
colnames
# 读取并整理数据
data_list <- lapply(file_paths, function(file_path) {
data <- read.csv(file_path, header = FALSE, stringsAsFactors = FALSE)
names(data) <- c("rowname", basename(file_path))
data.frame(rowname = data$rowname, data[[2]], stringsAsFactors = FALSE)
})
data_list
# 合并数据
merged_data <- Reduce(function(x, y) merge(x, y, by = "rowname", all = TRUE), data_list)
# 修改列名
names(merged_data)[-1] <- colnames
# 将合并的数据写入新的.csv文件
write.csv(merged_data, file = "merge.csv", row.names = FALSE)
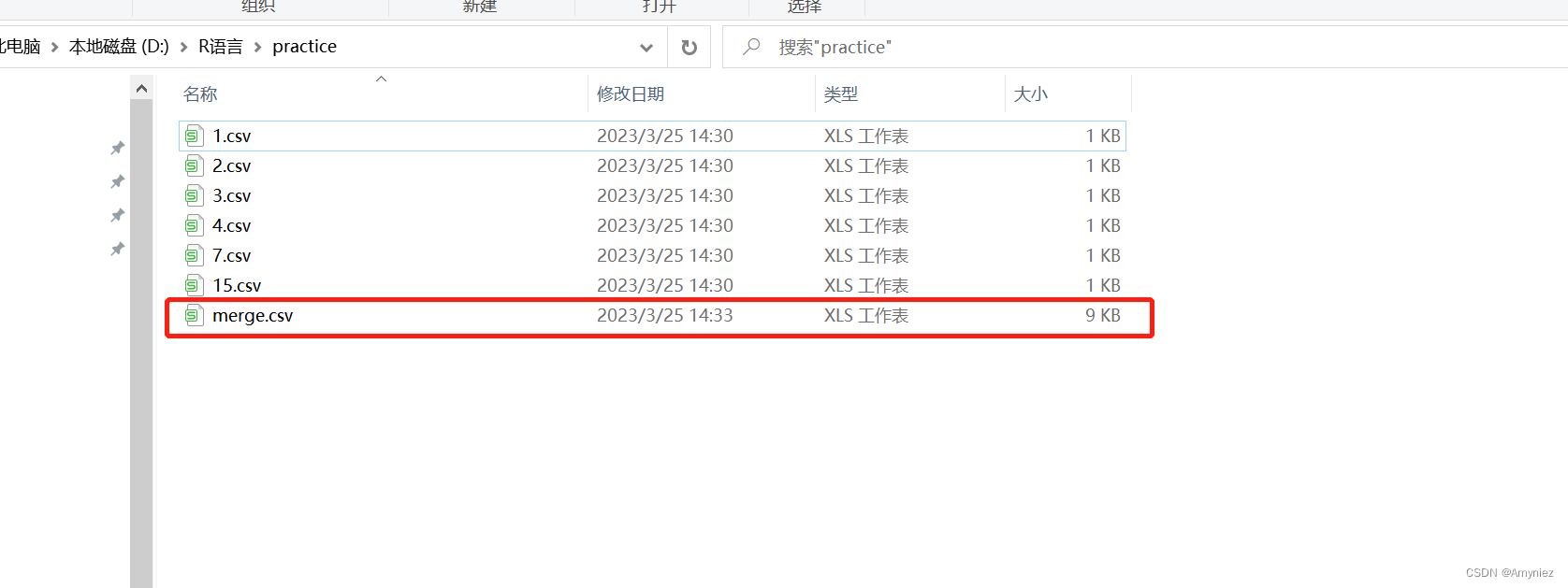
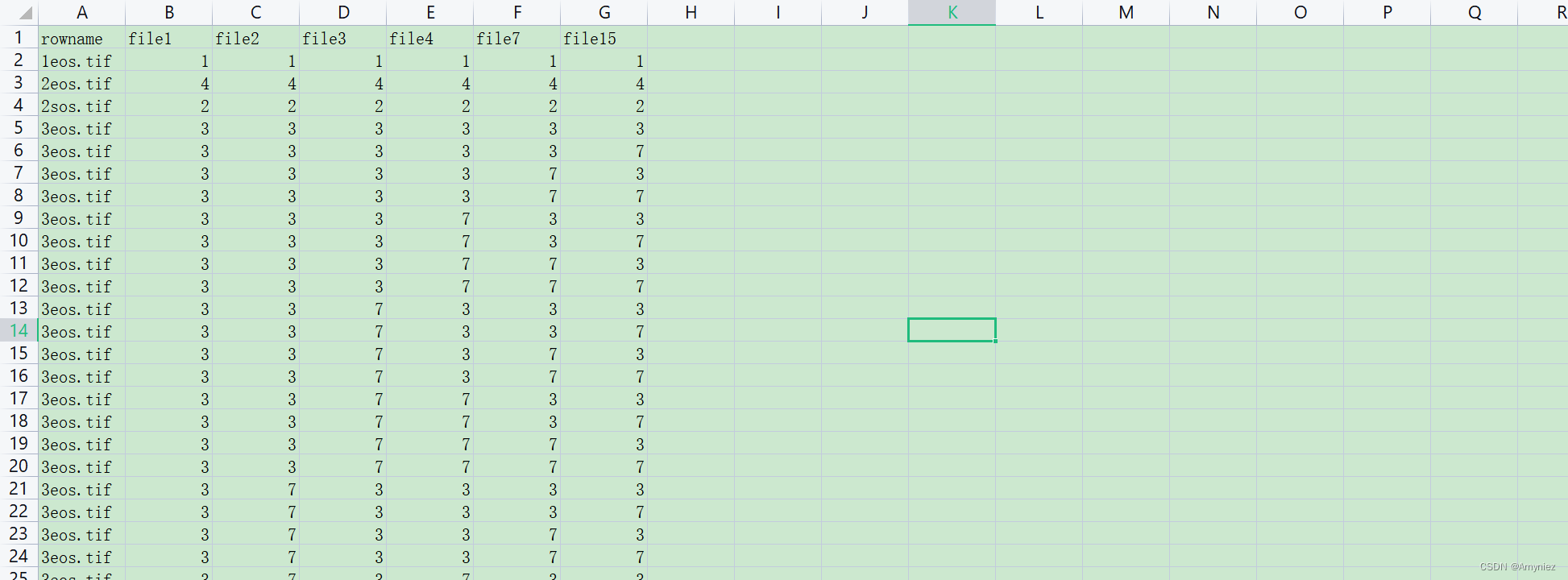
输出结果:


结果展示:
3. 实现2个Excel表相同数据的关联,并提取相同数据到新表
##----------------------------------------------------------------------------------
# @author:Jackson Zhao
# @time:2023/3/18 11:15:08
# 数据匹配:实现2个Excel表相同数据的关联,并提取相同数据到新表
library(dplyr)
library(readxl)
setwd("D:/lucc/anusplin2018")
a <- read_excel("yanjiuqu_qixiangzhan2018albers.xlsx")
b <- read_excel("0102.xlsx")
dim(a)
dim(b)
new_df <- inner_join(a, b, by = "区站号", multiple = "all")
dim(new_df)
new_df$平均气温 <- new_df$平均气温 * 0.1
head(new_df$平均气温)
new_df$`20-20时累计降水量` <- new_df$`20-20时累计降水量` *0.1
head(new_df$`20-20时累计降水量`)
head(new_df)
write.table(new_df,"0102new2.xlsx", sep = "\t", quote = FALSE, row.names = FALSE)
# 计算不重复数据的个数
unique_count <- n_distinct(unique(new_df[,1]))
unique_count
#c<- unique(new_df[,1]) # 218个不重复数据,with 208 more rows
4. 获取Excel表里面列名为TEM的所有数据并保存
##-------------------------------------------------------------------------------------
# @author:Jackson Zhao
# @time:2023/3/18 14:32:39
# 获取Excel表里面列名为TEM的所有数据并保存
library(readxl)
# 读取原始数据表
data <- read_excel("TEM_PRE.xlsx")
head(data)
dim(data)
# 匹配包含"TEM"的列名
tem_cols <- grep("PRE", names(data), value = TRUE)
# 选择包含"TEM"的列
new_data <- data[, tem_cols]
new_data
# 保存到新Excel表格中
write.table(new_data,"0102PRE.xlsx", sep = "\t",
quote = FALSE, row.names = FALSE)
5. 将文件夹中的.dbf文件转换为.xlsx文件
##-------------------------------------------------------------------------------------
# @author:Jackson Zhao
# @time:2023/3/24 17:42:12
# 将文件夹中的.dbf文件转换为.xlsx文件
# 导入需要使用的包
library(foreign)
library(openxlsx)
# 设置工作目录和输出目录
setwd("D:\\2007lucc\\clipforest_dbf\\8")
out_folder <- "8"
# 获取所有.dbf文件
dbf_files <- list.files(pattern = "\\.dbf$")
dbf_files
# 遍历所有.dbf文件
for (file in dbf_files) {
# 读取.dbf文件
dbf_data <- read.dbf(file)
# 构造输出路径和文件名
out_file <- file.path(out_folder, paste0(out_folder, tools::file_path_sans_ext(file), ".xlsx"))
# 将数据写入.xlsx文件
write.xlsx(dbf_data, out_file)
message(paste0("Converted ", file, " to ", out_file))
}
6. excel表格中生成重复数据
##--------------------------------------------------------------------------------------
# @author:Jackson Zhao
# @time:2023/3/24 19:20:03
# @description:文件夹下有多个Excel表格,每个excel表格中有2列数据,第一列列名为value,第二列列名为Count,
# 以第一列的数据为基础,将其生成对应的第二列数值个数的重复数据,例如,第一列数据为297,第二列数据为25,
# 即生成25个297,并将所有数据保存为一列。为每个Excel表生成一个对应的.csv文件,
# 文件名按照其对应的.xlsx的文件名命名
library(tidyverse)
# 设置工作目录
setwd("D:/clip/8")
# 获取所有Excel文件的文件名
excel_files <- list.files(pattern = "*.xlsx")
excel_files
# 定义一个函数,用于处理单个Excel文件
process_excel <- function(file) {
# 读取Excel文件
df <- read_excel(file)
# 将数据展开成重复的向量
values <- rep(df$Value, df$Count)
# 将向量转换为数据框,并且将列名设置为"value"
output_df <- data.frame(value = values)
# 构造输出文件名,并将数据保存为CSV文件
output_file <- paste0(tools::file_path_sans_ext(file), ".csv")
write_csv(output_df, output_file)
}
# 遍历所有Excel文件,并处理每个文件
lapply(excel_files, process_excel)
7. 表格数据按列合并!!!
这里我花了很多时间编写,得出来以下的结论:
注意:R语言合并数据时要求所有数据的行数相同,否则无法进行合并,会报错:
Error in data.frame(…, check.names = FALSE) :
参数值意味着不同的行数: 33, 1064
这个代码假设所有.csv文件都在同一个文件夹中,并且它们都只有一列数据。它将所有数据列并排放置在新的csv文件中,其中列名是原始文件名(不带.csv后缀)。如果某些csv文件中的行数不同,则该代码将生成带有缺失值的数据框。
代码思路:
1、找到所有.csv文件中最大的行数,a;
2、将所有.csv文件用“-1”填充到最大行数;
3、数据合并
##----------------------------------------------------------------------------------------
# @author:Jackson Zhao
# @time:2023/3/24 23:51:06
# @description:设置工作目录为该文件夹
library(tidyverse)
setwd("D:\\clipforest_dbf\\data")
# 获取文件夹中的所有.csv文件
csv_files <- list.files(path = "D:\\clipforest_dbf\\data", pattern = "\\.csv$")
# 定义一个函数用于读取文件并返回行数
get_row_count <- function(file_path) {
# 读取csv文件
df <- read.csv(file_path, header = TRUE)
# 返回行数
nrow(df)
}
# 使用lapply函数调用get_row_count函数并返回行数向量
row_counts <- unlist(lapply(csv_files, get_row_count))
row_counts
# 打印每个文件的行数
cat("文件名\t行数\n")
for (i in seq_along(csv_files)) {
cat(paste0(basename(csv_files[i]), "\t", row_counts[i], "\n"))
}
# 找到最大的行数a
a <- max(row_counts)
a
# 循环处理每个.csv文件
for (file in csv_files) {
# 读取数据
temp_data <- read.csv(file, header = FALSE)
# 获取第一列的行数
n_rows <- nrow(temp_data)
# 创建长度为1065的向量,填充为-1
new_col <- rep(-1, a)
# 将读取的数据填充到新的向量中
if (n_rows >= a) {
new_col <- temp_data[1:a, 1]
} else {
new_col[1:n_rows] <- temp_data[, 1]
}
# 将新向量转换为数据框,并写入新的.csv文件中
new_data <- data.frame(new_col)
write.csv(new_data, file = paste0(file, "_processed.csv"), row.names = FALSE)
}
# 指定文件夹路径和要读取的csv文件列表
csv_files <- list.files(folder_path, pattern = "*.csv", full.names = TRUE)
csv_files
# 读取所有csv文件并将它们合并到一个数据框中
data_list <- lapply(csv_files, function(x) read_csv(x, show_col_types = FALSE))
data_list
merged_data <- bind_cols(data_list)
# 重命名列名
colnames(merged_data) <- gsub(".csv", "", basename(csv_files))
# 保存合并后的数据框为.csv文件
write_csv(merged_data, "merge.csv")
write.xlsx(merged_data, "merge.xlsx")